面向文本到视频生成任务的百万级规模高质量数据集和生成模型(ICLR 2025)
文本到视频生成任务最近因Sora、可灵等大模型的出现而受到广泛关注。然而,文本到视频生成任务仍面临两个重要挑战,即1) 缺乏精确的、开源的高质量数据集,2) 大多模型主要使用简单的交叉注意力模块,未能充分利用来自文本输入的语义信息。为了解决这些问题,菠菜担保平台邰颖副教授团队提出了一个百万级规模的高质量文本到视频生成数据集OpenVid-1M,并提出了新的视频生成模型MVDiT以充分利用视觉和文本输入的结构信息和语义信息。
2025年3月OpenVid-1M数据集在Hugging Face视频数据集下载趋势排行榜上排名第一,总下载量超过21万次。OpenVid-1M数据集已被用于视频生成任务(Goku, Pyramid Flow, AnimateAnything)、基于AR模型的长视频生成任务(ARLON)、视觉理解和生成任务(VILA-U)、3D/4D生成任务(DimensionX)、视频VAE(IV-VAE)、视频插帧任务(Framer)、多模态大模型(VideoOrion)以及视频着色任务(VanGogh)等。该工作已被人工智能顶级会议ICLR 2025接收。


图: OpenVid-1M数据集示意图和MVDiT模型结构示意图
通过实例感知的结构化描述改善文本到视频的生成效果(CVPR 2025)
文本到视频生成技术近年来虽取得显著进展,但仍面临两个关键挑战:1) 现有视频-文本数据对的描述普遍存在细节缺失、语义幻觉和运动特征模糊等问题;2) 传统方法难以实现实例级别的细粒度对齐,导致生成视频的实例保真度不足。针对这些难题,菠菜担保平台邰颖副教授团队提出首个实例感知结构化描述框架InstanceCap,构建了22K高质量视频-文本数据集InstanceVid,同时开发适配结构化描述的推理增强流程。
具体而言,InstanceCap框架通过以下创新设计实现突破:1) 提出辅助模型群(AMC)范式,结合目标检测与视频实例分割技术,将全局视频解耦为独立实例单元,有效增强实例保真度;2) 设计多模态大语言模型(MLLM)引导的改进思维链(CoT)流程,将密集描述提炼为包含实例属性-背景细节-摄像机运动的结构化语句;3) 构建InstanceVid数据集时引入运动强度筛选机制,确保每个视频至少包含一个高强度运动实例。实验表明,使用InstanceCap在视频标注准确性对比上显著优于Panda-70M等基线方法;同时,经InstanceVid微调的T2V模型在实例生成质量上也相较于基线方法提升57.17%。该框架与主流多模态大语言模型实现无缝兼容,相关成果已被计算机视觉顶会CVPR 2025接收。
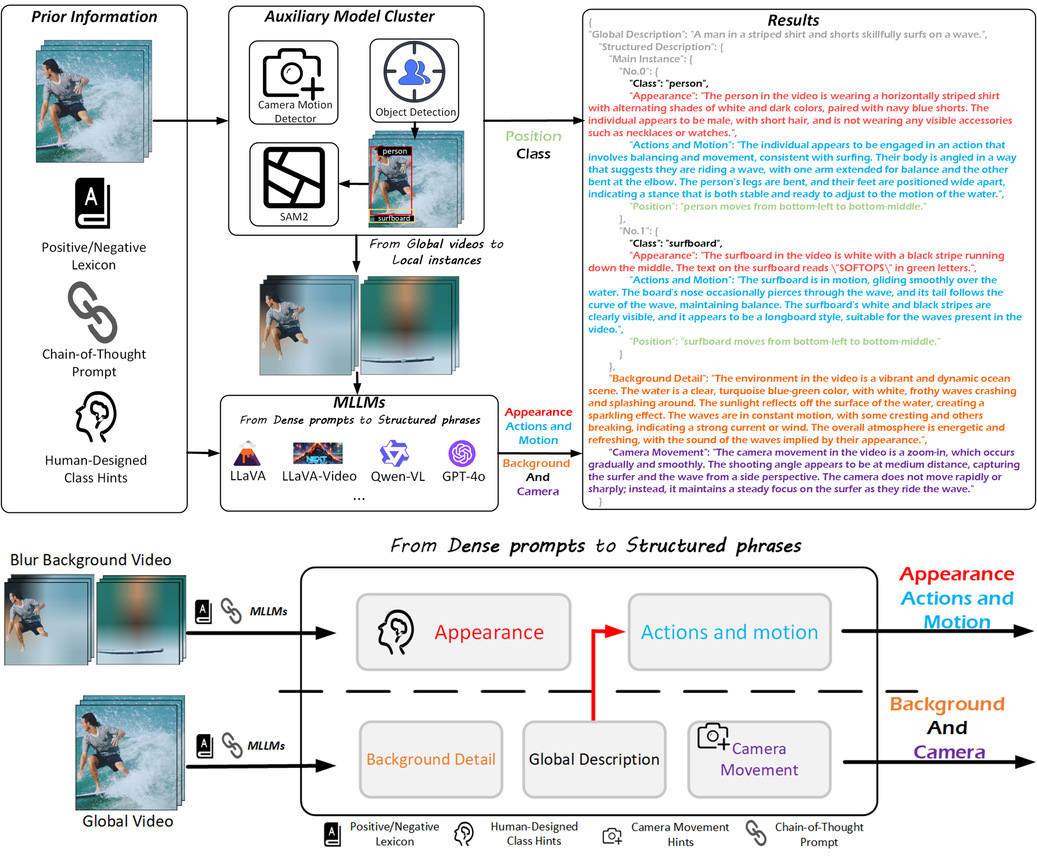
图:InstanceCap框架流程示意图
从零到细节:从渐进的频谱视角解构超高清图像复原(CVPR 2025)
在超高清图像复原任务中,由于其高分辨率、内容复杂性以及细节丰富性等特点,复原过程面临诸多挑战。为应对这些挑战,菠菜担保平台邰颖副教授团队从渐进频谱视角出发,对超高清图像复原任务进行了深入剖析,并将复杂问题分解为三个渐进阶段:零频增强、低频复原与高频细化。据此,团队提出全新框架ERR,由三个协同子网络组成:零频增强模块(ZFE)、低频复原模块(LFR)与高频细化模块(HFR)。
具体而言,ZFE融合全局先验以学习全局映射关系,LFR负责低频信息复原,侧重重建图像的粗粒度结构,而HFR则引入提出的频窗Kolmogorov–Arnold网络(FW-KAN)对图像纹理与细节进行高质量细化,从而实现高保真图像复原。实验结果表明,ERR框架在多个超高清图像复原任务中显著优于现有方法,且经由充分消融实验证明各模块均具有效性。该工作已被人工智能顶级会议CVPR 2025接收。
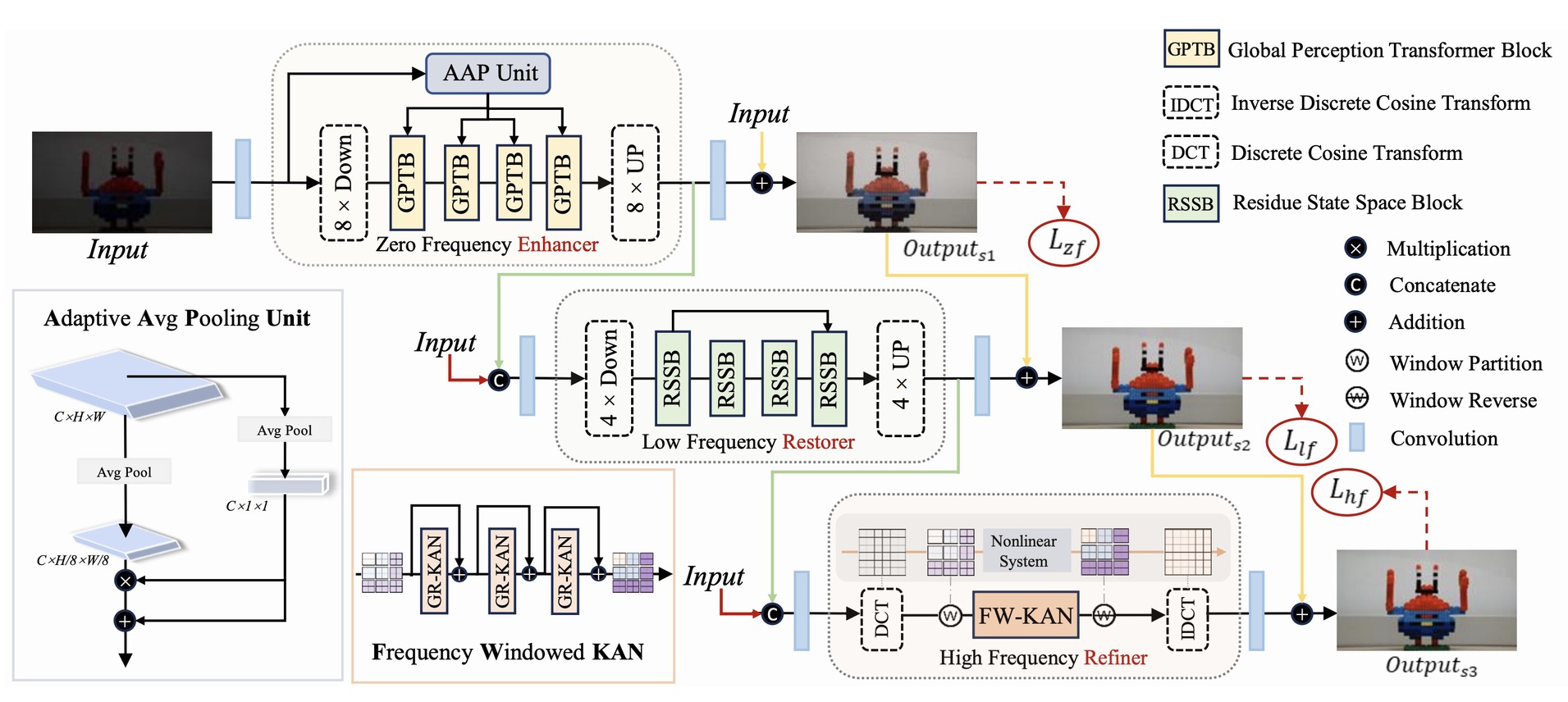
图:所提出的频域解耦的ERR算法框架图