Matrix3D: 摄影测量大模型 (CVPR 2025 Highlight)
三维内容创建(3D Content Creation)是混合现实、数字孪生和影视游戏等众多应用中的关键技术,但现有方法通常将“生成”与“重建”视为两个独立任务:重建依赖密集多视图输入,而生成则专注于于单视角或稀疏视角输入,二者难以统一建模。同时,现有三维建模流程(如 SfM、MVS、NVS)任务割裂、步骤繁多,难以扩展。
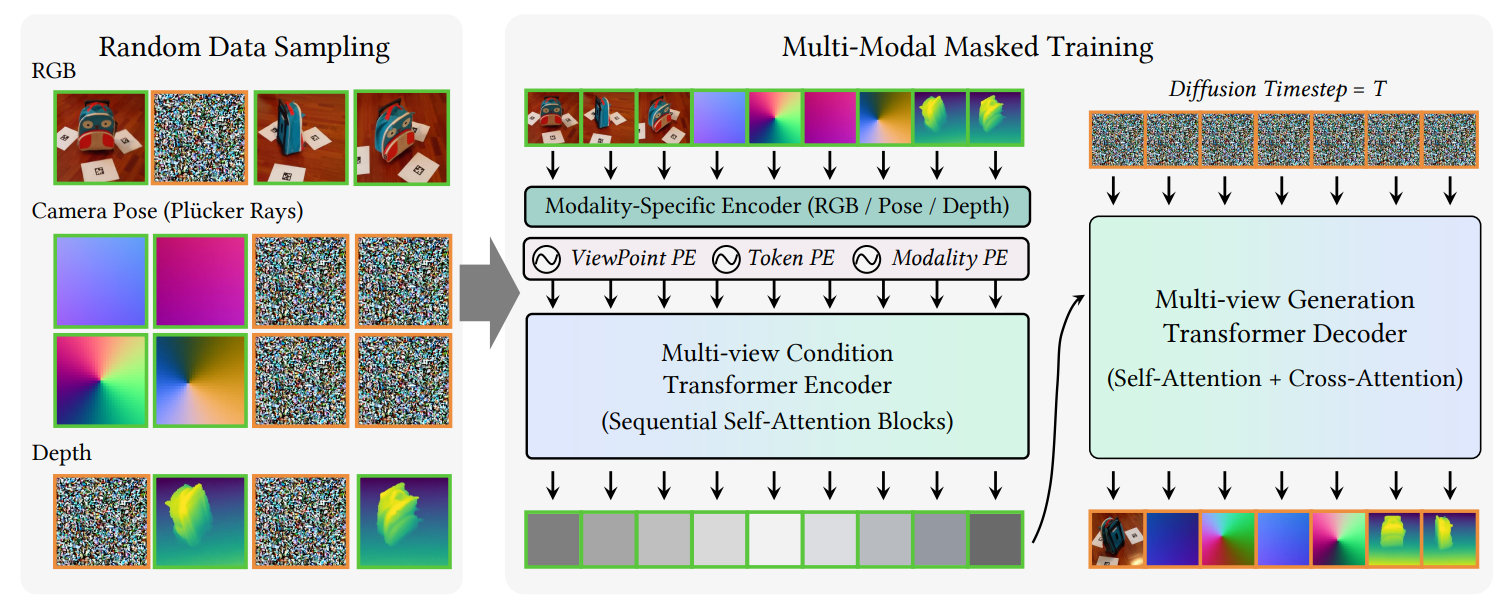
为解决上述问题,菠菜担保平台姚遥副教授团队与Apple,香港科技大学联合提出 Matrix3D——首个支持多任务、多模态输入输出的三维摄影测量大模型。Matrix3D通过掩码学习,建模RGB图像、相机位姿,深度图等模态,统一了三维生成和摄影测量的各个子步骤,实现从任意模态推理其余模态。通过结合 3D Gaussian Splatting技术,Matrix3D 可以高质量地从未知相机位姿的稀疏视角图像输入恢复完整三维结构,显著优化三维建模流程。得益于创新性的多模态扩散Transformer结构和跨模态掩码训练策略,Matrix3D能灵活处理不完整模态输入,支持任意组合的输入输出配置,并在多个子任务上实现最优性能。该工作已被计算机视觉顶级会议 CVPR 2025 接收,并选为 Highlight论文。
预训练光流大模型先验的三维高斯辐射场重建 (ICLR 2025)
三维高斯溅射(3DGS)在实现快速训练与推理速度的同时,能获得优异的渲染质量。然而,3DGS的优化过程缺乏显式几何约束,导致在观测输入视角稀疏或缺失的区域难以实现完整的几何重建。本研究尝试通过将预训练匹配先验引入3DGS优化过程来解决该问题。菠菜担保平台姚遥副教授团队提出流蒸馏采样(FDS)技术,该技术利用预训练的匹配几何知识来增强高斯辐射场的精度。具体而言,FDS采用策略性采样技术来采样输入视角相邻的未观测视角,通过从匹配模型计算两个视角的光流(先验流)来指导由3DGS几何结构解析计算得到的辐射流。在深度渲染、网格重建和新视角合成方面的综合实验表明,FDS相较现有最优方法具有显著优势。该工作已经被机器学习顶级会议ICLR 2025接收。
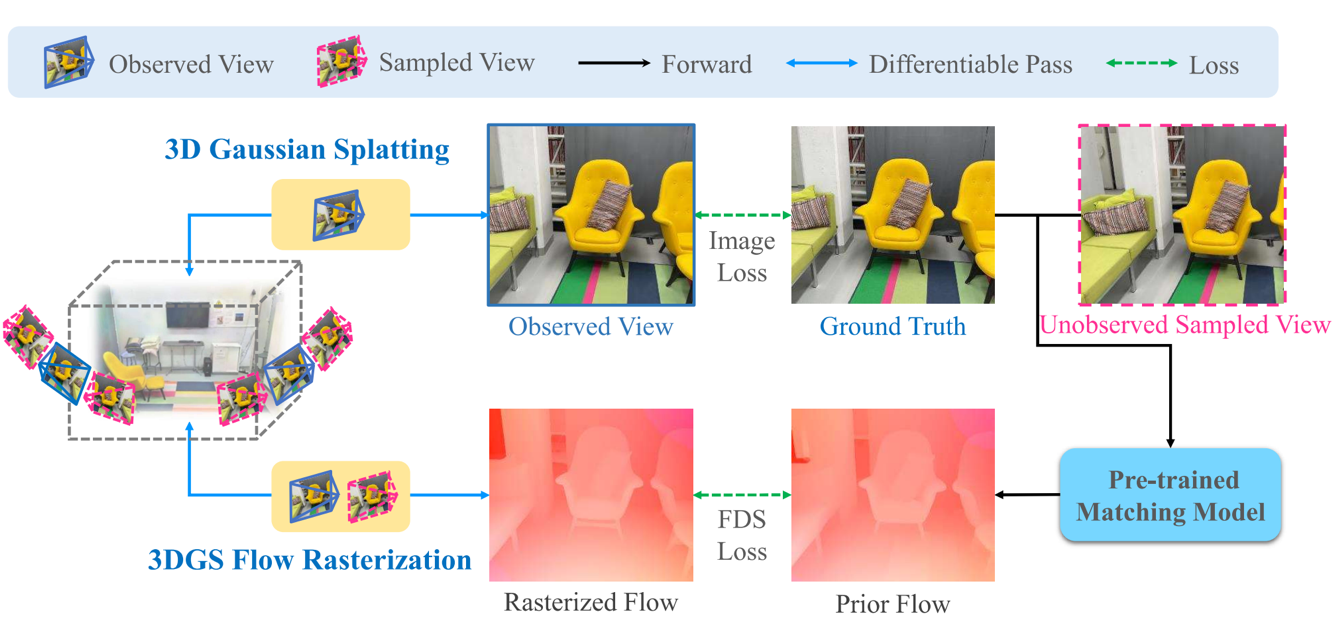
流蒸馏采样(FDS)的流程图
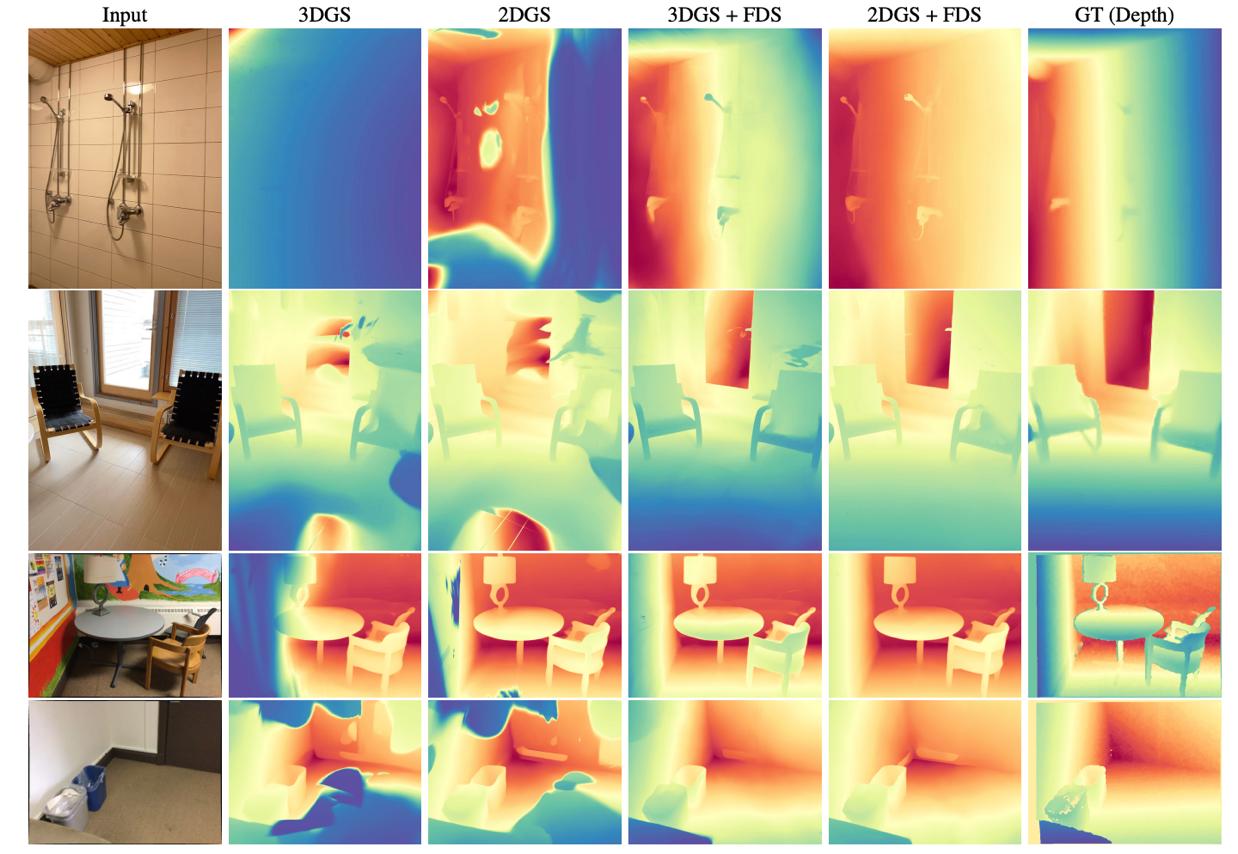
在MushRoom数据集和ScanNet数据集上的对比结果
EasyHOI: 大模型驱动的手-物交互重建新方案 (CVPR 2025)
从单视角图像中重建手-物交互,是一项基础但具有挑战性的任务。与基于视频、多视角图像或预定义3D模板的方法不同,单视角重建受限于图像中固有的多义性和遮挡问题,这些问题显著影响了重建的准确性。此外,手部姿态的多样性、物体形状和尺寸的多变性,以及复杂的交互模式进一步增加了该任务的难度。

为解决上述问题,菠菜担保平台龙霄潇副教授团队与上海科技大学,香港大学,德国马普所,德州农工大学联合提出EasyHOI--一套创新的手-物交互重建方案。EasyHOI充分利用当前基础模型在处理真实场景图像时表现出了强大的泛化能力,为手-物交互的重建提供了可靠的视觉和几何先验。在此基础上,EasyHOI设计了一种基于视觉和几何先验的优化方法,使重建结果不仅满足物理约束,还能与2D输入图像内容保持一致性。得益于大模型的生成能力与泛化能力,EasyHOI在多个公开数据集上均超过现有基线方法,在重建的精度和鲁棒性上具有显著优势,能够从多样化的真实手-物交互图片中准确还原物体的几何形状及交互细节。这一成果为单视角手-物交互重建任务提供了全新的技术方案,展现了广阔的应用前景。该工作已被计算机视觉顶级会议 CVPR 2025 接收。
FATE:面向单目视频的高保真可动画三维头部重建 (CVPR 2025)
在高质量三维头部重建任务中,如何通过便捷获取的单目视频生成可编辑、可动画的全头部头像始终是一项具有挑战性的关键问题。尽管近年来在渲染性能与控制能力方面取得了一定进展,但仍面临重建不完整、表达效率低等问题。针对这一问题,菠菜担保平台朱昊助理教授团队提出了一种新方法 FATE,用于从单目视频中重建可编辑的完整三维头部头像。
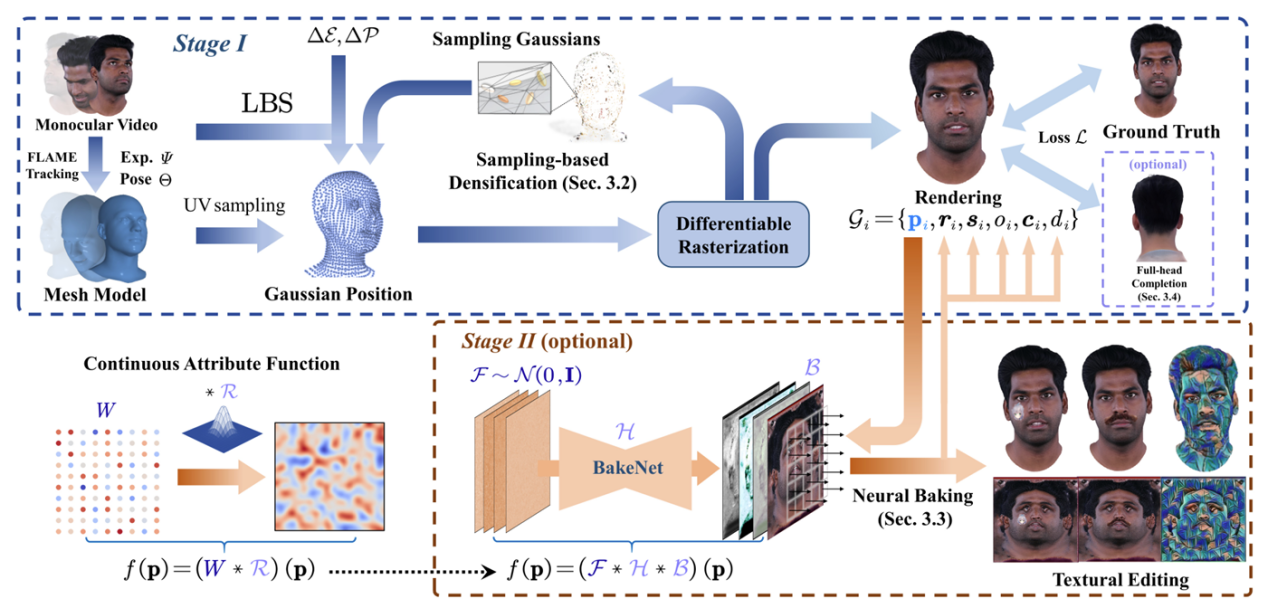
具体而言,FATE方法通过引入基于采样的点密度增强策略,实现空间点位的优化分布,显著提升渲染效率。同时,提出一种神经烘焙技术,将离散 Gaussian 表达转化为连续属性图,从而支持更直观的外观编辑。此外,FATE还设计了一个通用的外观补全框架,用于恢复非正面区域的头部外观,实现完整的360度可渲染三维头像重建。实验结果表明,FATE在定性和定量评估中均优于现有方法,达到了当前最优性能。该工作已经被计算机视觉顶级会议CVPR 2025接收。
IDOL:面向从单张图像重建可驱动3D数字人的高效解决方案 (CVPR 2025)
在虚拟现实、游戏以及3D内容创作等领域,“如何从单张图像快速且高保真地重建可驱动的全身3D人体”一直是一个备受关注的难题。由于人体姿态与形态的高度复杂性,以及现有数据的匮乏,传统方法要么依赖于多视角三维数据集,泛化性和精度难以平衡,要么在实时性上难以兼顾,常常无法满足实际应用需求。为解决这一挑战,菠菜担保论坛大全菠菜担保平台朱昊助理教授团队与腾讯AI Lab、中科院、清华大学共同提出了全新方案IDOL,并在2025 CVPR上发表,引发业界高度关注(项目主页访问量已突破3500次)。
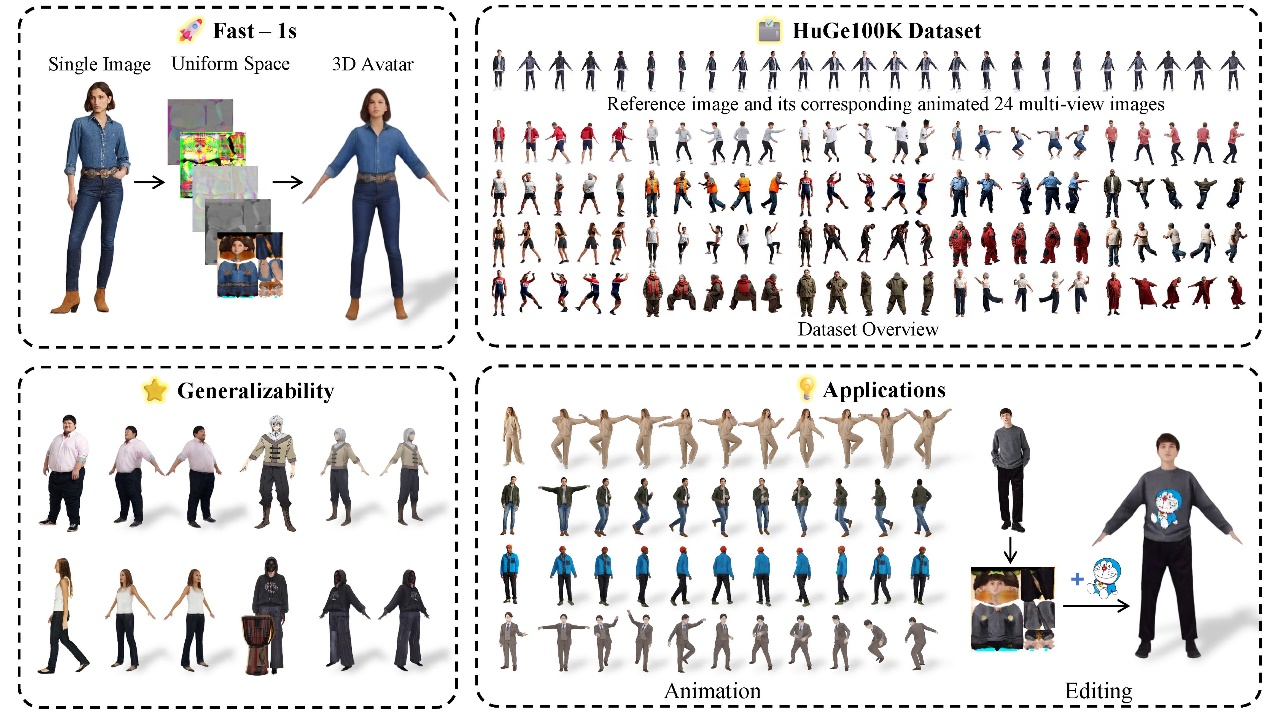
在这一方法中,研究者们首先利用自研的多视点生成模型构建了大规模高真实感的人体数据集HuGe100K,然后训练了一个前馈式的Transformer网络,只需1秒便能从单张图像生成高分辨率、可直接驱动的3D人体模型。该模型在视觉真实感、泛化能力和实时性上均取得了突破性成果,还支持后续的渲染、动画和形状/纹理编辑等多种应用。目前该工作已经开源,详见https://yiyuzhuang.github.io/IDOL。