
On February 5th, 2025, A research team from the Technical University of Munich, Nanjing University, Sun Yat-sen University and Tsinghua University in Germany has published a groundbreaking study - Preserving and Combining Knowledge in Nature Machine Intelligence, a top international journal Robotic Lifelong Reinforcement Learning . This study proposes a lifelong reinforcement learning framework for robots called LEGION, which successfully solves the problem of how to retain and combine knowledge in the continuous learning process of robots, and takes an important step for robots to realize human-like intelligence.
This study not only demonstrates the excellent performance of robots in complex tasks, but also significantly improves the task understanding and execution capabilities of robots by combining language embedding and non-parametric Bayesian models. The research team verified the extensive application potential of LEGION framework in the real world through experiments, especially in long-term tasks. The authors included Meng Yuan, Bing Zhenshan, Yao Tongtong, and Alois Knoll, professors at the Technical University of Munich, Germany; Professor Huang Kai, School of Data Science and Computer Science, Sun Yat-sen University; National Key Laboratory of New Computer Software Technology, Nanjing University; Professor Gao Yang, School of Intelligent Science and Technology, Nanjing University (Suzhou) And Sun Fuchun, professor of Computer Science and Technology at Tsinghua University. Dr. Bing Zhenshan is affiliated with the National Key Laboratory of New Computer Software Technology of Nanjing University and the School of Intelligent Science and Technology of Nanjing University (Suzhou).
*Why study lifelong learning in robots?*
Human beings have the ability of lifelong learning, the ability to continuously accumulate knowledge and adapt to new task scenarios, and this ability is considered to be the key mechanism to achieve general intelligence. However, current AI systems based on deep reinforcement learning, while excellent at specific tasks, often suffer from catastrophic forgetting when faced with a continuous flow of tasks, that is, when the agent learns a new task, the parameters of the neural network are overwritten by new data, causing it to forget previously learned skills. Therefore, it is difficult for traditional robot reinforcement learning models to maintain existing knowledge and expand on it like humans do. While traditional multi-task learning methods can alleviate this problem to some extent, they often require robots to access all pre-defined task distributions simultaneously while training, which is far from the actual learning process for humans. This limitation seriously hinders the application of robots in complex environments.
To solve this problem, The research team proposes a new lifelong Reinforcement Learning framework for robots, namely LEGION (Language Embedding based Generative Incremental Off-policy Reinforcement Learning) Framework with Non-parametric Bayes). By combining Bayesian non-parametric models and language embedding techniques, the framework enables robots to continuously accumulate knowledge in a continuous flow of tasks, and to solve complex long-term tasks by combining and reapplying acquired knowledge.
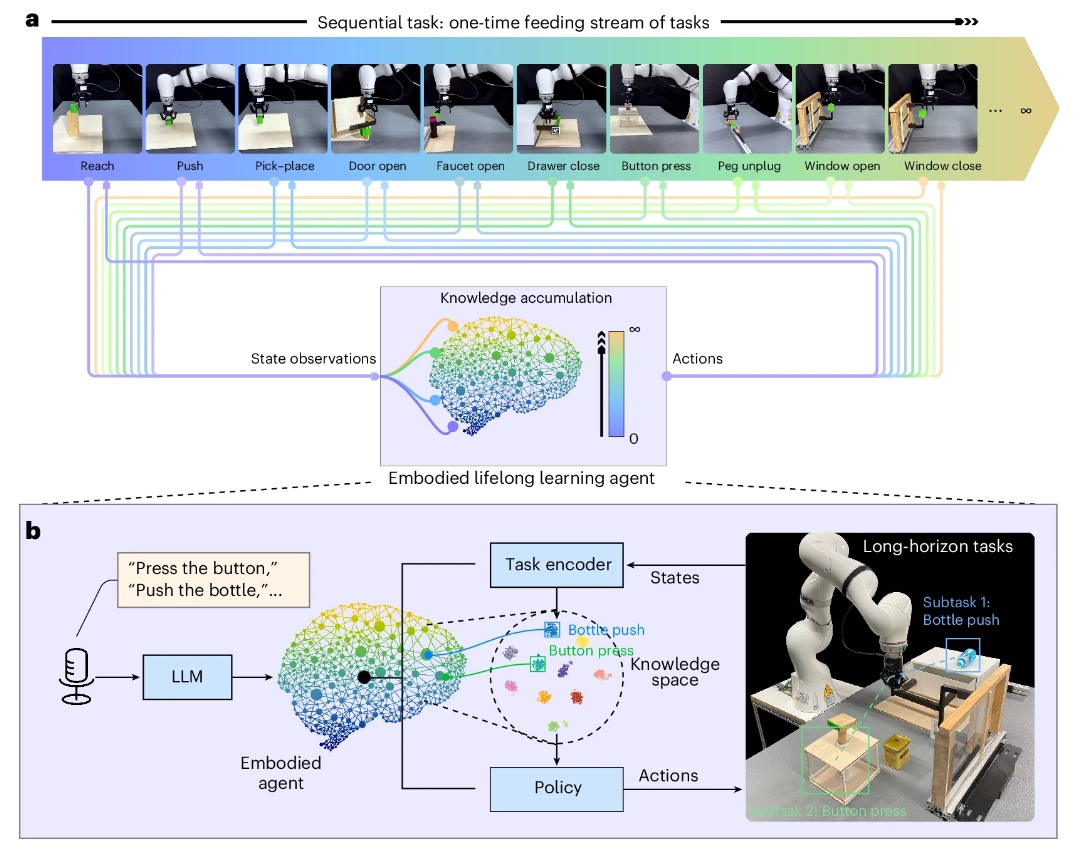
Figure 1 Conceptual diagram of the lifelong reinforcement learning process of the robot. a. Presents the general concept of the lifelong reinforcement learning process. Unlike traditional multi-tasking learning methods, lifelong reinforcement learning agents can master each task in turn in a stream of tasks and continuously accumulate knowledge throughout the process. The concept mimics the human learning process. b. Presents our proposed lifelong learning framework. We use verbal commands to direct deployed robots to perform scheduling tasks. Robots accomplish these tasks by combining and reapplying acquired knowledge.
*Core innovation of LEGION framework*
*Bayesian nonparametric knowledge space*
One of the core innovations of the LEGION framework is its knowledge space based on the Dirichlet Process Hybrid Model (DPMM). Different from the traditional parametric model, DPMM can dynamically adjust the complexity of the model according to the new data in the task flow, and automatically generate new knowledge components to store the information of new tasks. This non-parametric design allows the robot to flexibly expand its knowledge space when faced with an unknown number of tasks, avoiding forgetting previously acquired knowledge.
*Language embedding enhances task understanding*
In order to further improve the robot's ability to understand tasks, LEGION framework also introduces language embedding technology. Through a pre-trained large language model (LLM), the robot is able to convert the task instructions described in natural language into semantic embeddedness, which leads to a better understanding of the contextual information of the task. This language embedding not only helps the robot infer the current task more accurately, but also provides it with richer semantic information, enabling it to make smarter decisions when faced with complex tasks.
*Knowledge combination and reapplication*
Another important feature of LEGION framework is its ability to solve complex long-term tasks through knowledge combination and reapplication. For example, in the long-term task of clearing the table, the robot needs to complete several sub-tasks such as pushing the cup, opening the drawer, and pressing the button in turn. By combining and reapplying previously acquired knowledge, LEGION framework can flexibly adjust the execution order of tasks and efficiently complete complex long-term tasks.
*Experimental results: Embodied intelligence's lifelong learning ability*
The research team verified the effectiveness of LEGION framework through a series of experiments. The experiments range from single-task performance for lifelong learning to complex combinations of long-term tasks, demonstrating the potential of robots for a wide range of real-world applications.
*Performance of long-term tasks*
The research team tested the effectiveness of the framework using the KUKA iiwa robotic arm. In the long-term task experiment, the robot was required to complete a series of complex subtasks, such as clearing the table or making coffee. These tasks require the robot to be able to flexibly combine knowledge previously learned from lifelong reinforcement learning tasks and perform them sequentially. Video 1 shows the robot performing the task of clearing the table. By combining and reapplying previously learned knowledge, the robot successfully completed all subtasks, demonstrating its excellent performance in complex tasks.
This knowledge combination not only has high flexibility and generalization ability, but also breaks through the limitations of traditional imitation learning. Unlike traditional behavioral cloning methods, which rely on pre-defined task order, the LEGION framework allows robots to freely arrange and combine learned skills when completing long-term tasks. Video 2 shows the robot's free skill combination demonstration while performing the task of clearing the table, which fully demonstrates its flexible ability to adapt to complex tasks.
*The performance of lifelong reinforcement learning*
In addition, the researchers evaluated the LEGION architecture's performance on a single task during lifelong learning. The researchers set the robot to perform multiple tasks, such as pressing a button, pushing a bottle, turning on a tap, and closing a drawer (Figure 2). Robots do not forget previously learned tasks during training, but gradually accumulate experience and acquire relevant skills to perform more complex tasks when needed. What's more, when the robot is faced with a long-term task (such as cleaning the desktop), it can flexibly invoke learned task skills (such as pressing a button + pushing a bottle) to complete the entire task without the need for additional demonstration from a human. This ability is extremely valuable in real-world applications, such as home service robots or automated industrial robots that can perform new tasks based on environmental requirements without repeated training. The actual machine performance is shown in video 3.

FIG. 2 Single-task performance of robots in the real world after lifelong reinforcement learning. A snapshot of the robot during the completion of each operational task is shown.
*Knowledge retention and forgetting*
To assess the LEGION framework's performance on knowledge retention, the research team demonstrated changes in knowledge space through t-SNE visualization and statistical analysis. Figure 3 shows the clustering of the knowledge space after the robot learns different tasks. As can be seen, as the number of tasks increases, the knowledge space can be dynamically adjusted to ensure the effective retention of new knowledge. In addition, the experiment also shows that LEGION framework can quickly recall the previously learned knowledge in multiple learning cycles, demonstrating its powerful ability in small sample learning.

Figure 3 t-SNE snapshot of knowledge space. A-e. Shows the t-SNE projection of knowledge space after the robot has learned two tasks (a), four tasks (b), six tasks (c), eight tasks (d), and all ten tasks (e). f. Shows the t-SNE projection after the first training cycle (circle) and the second training cycle (cross). Notably, the inference results of the second training cycle are incorporated into the corresponding knowledge set retained in the first cycle.
*Less sample memory reactivation*
In a small sample knowledge recall experiment, the research team demonstrated the performance of LEGION framework in the case of intermittent playback. Figure 4 shows how the robot performs in multiple learning cycles. It can be seen that even after a long pause, the robot was able to quickly recall what it had previously learned and showed a higher success rate in subsequent tasks. This result is consistent with the memory consolidation theory in biology, and further verifies the validity of LEGION framework.
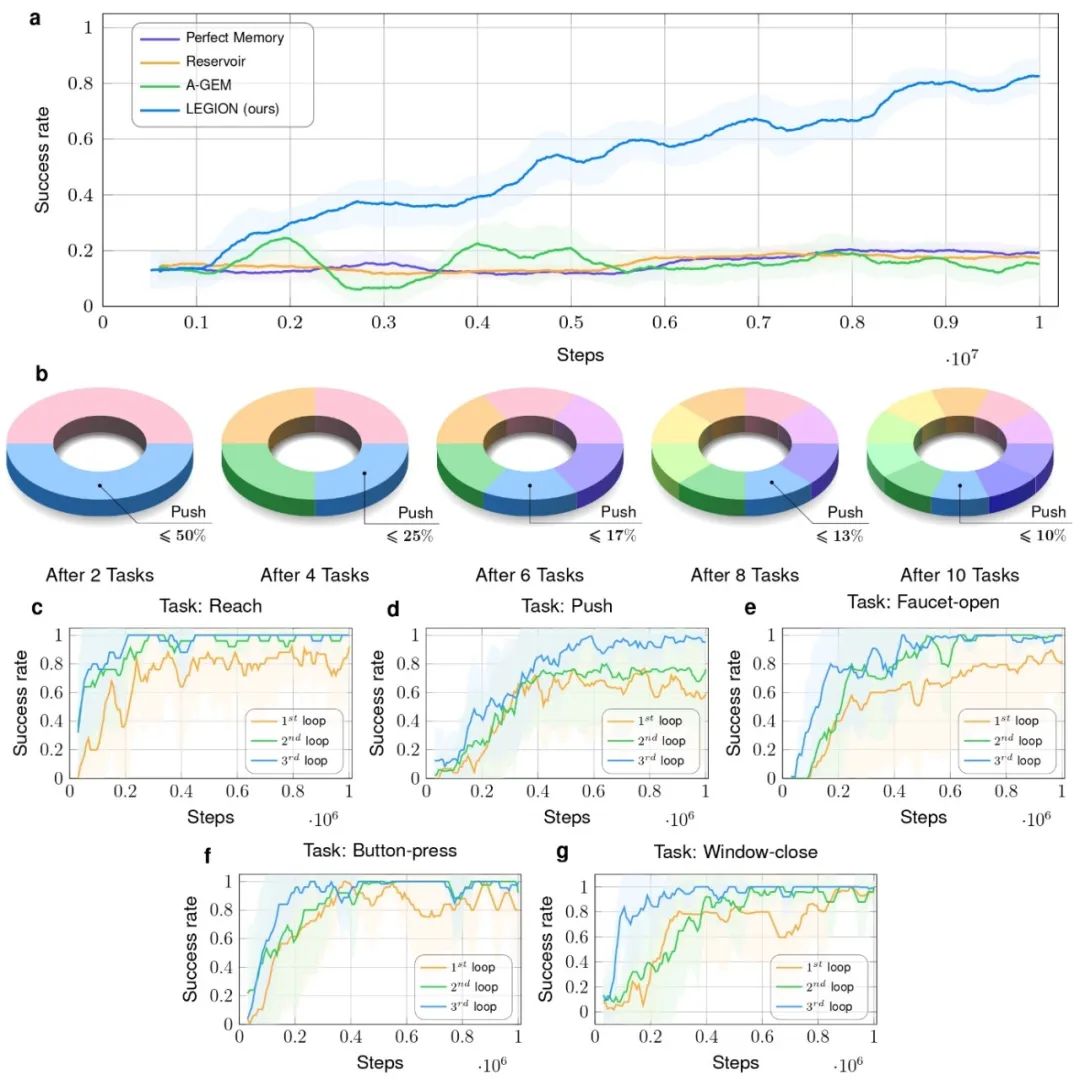
Figure 4 Replays the assessment of contributions to knowledge recall. a. The average success rate of LEGION framework compared with three replay-based lifelong learning methods is shown. The graph shows that the LEGION framework consistently outperforms other methods throughout the task sequence, demonstrating a steady improvement in its success rate. b. It shows the evolution of the push task data in the training batch. While the batch size remained the same, as the number of learning tasks increased, the percentage of data pushed tasks gradually decreased from the initial 50 percent to 10 percent. C-g. Demonstrated low-sample knowledge recall performance on the reach (c), push (d), tap on (e), button pressed (f), and window closed (g) tasks. The robot trains five selected tasks in turn in three repetitive loops, with the buffer capacity limited to three tasks at a time.
*Training and deployment*
Figure 5 shows the detailed training and deployment process of the LEGION framework. In the policy training stage: LEGION framework receives language semantic information and environment observation as input, generates policy decisions and outputs action patterns. Unlike traditional multi-task learning methods, LEGION trains only one task at a time, ensuring that knowledge can be accumulated gradually. In the real physical world deployment phase: In the real world demonstration, the agent parameters remain unchanged, and the robot receives the input signal from the real world hardware and outputs the corresponding action signal. To ensure a seamless interface between simulation and the real world, the framework also introduces Sim2Real and Real2Sim modules to handle data conversion and calibration.
Through this phased training and deployment, LEGION framework can not only learn efficiently in the simulation environment, but also flexibly apply the learned knowledge in the real world, demonstrating its strong adaptability in complex tasks. See Video 4 for a detailed introduction to the architecture.
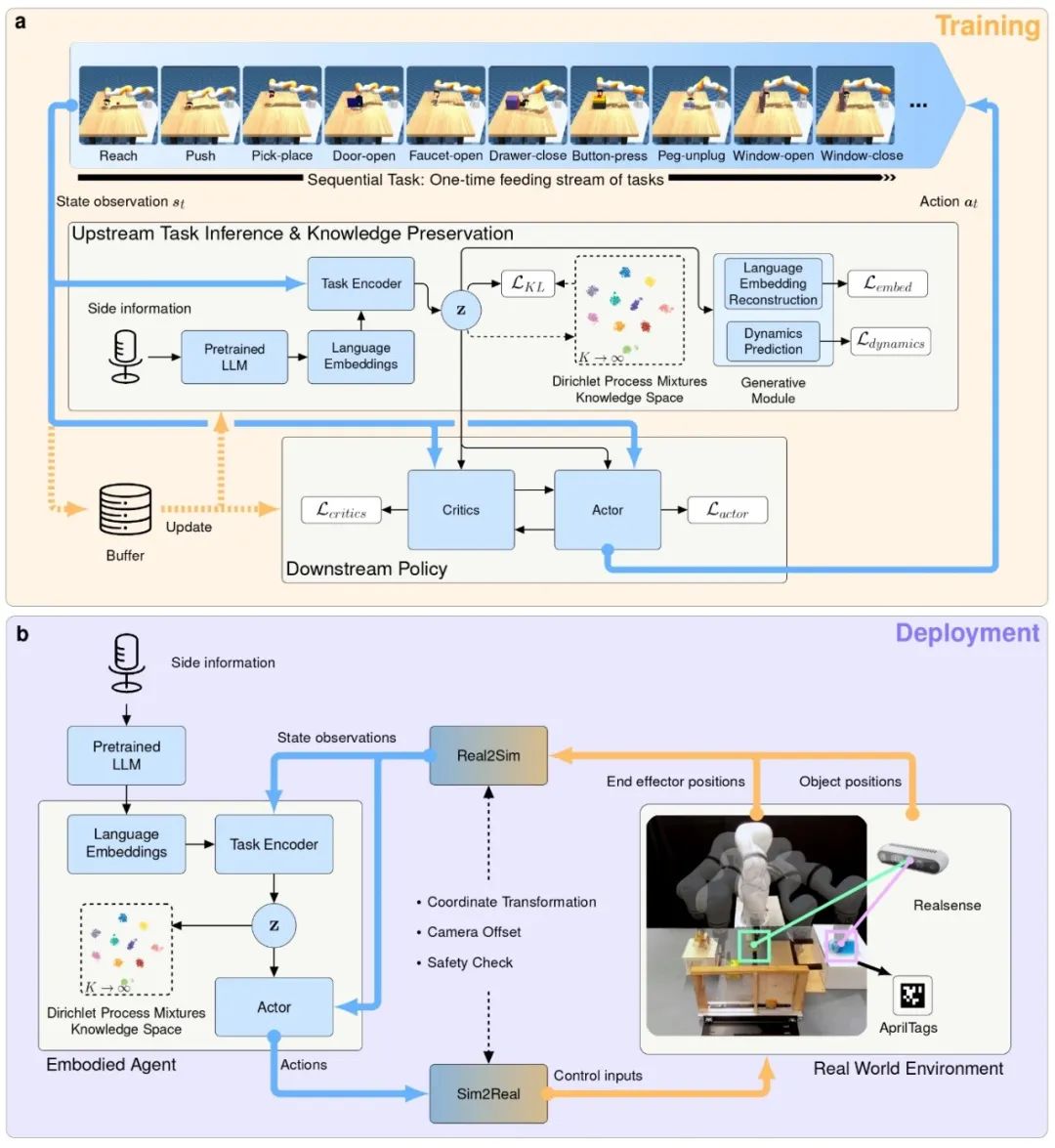
Figure 5 Training and deployment overview of LEGION framework. a. Training phase. The framework receives linguistic semantic information and environmental observations as inputs, generates policy decisions and outputs action patterns. It trains one task at a time. b. Deployment phase. In a real-world demonstration, the proxy parameters remain the same, and the proxy receives input signals from real-world hardware and outputs corresponding action signals. The Sim2Real and Real2Sim modules process data to bridge the gap between simulation and the real world.
*Future Vision: Towards general Intelligence*
The success of the LEGION framework not only demonstrates the potential of robots in lifelong learning, but also provides a new direction for the development of intelligent robots in the future. The research team said that in the future, it will further optimize the framework to explore more stable learning without playback buffers, and try to apply the framework in more challenging scenarios such as zero-sample reasoning. In addition, the research team also plans to extend the LEGION framework to unstructured, dynamic environments to improve the robot's generalization ability and robustness in complex scenarios. By combining language models and continuous learning techniques, LEGION framework is expected to enable a wider range of intelligent applications in the future, driving the further development of robotics.
*conclusion*
The proposal of LEGION framework marks an important breakthrough in the field of robot lifelong learning. By combining non-parametric Bayesian knowledge space and language embedding, LEGION not only solves the knowledge retention problem of robots in continuous learning, but also demonstrates its excellent performance in complex tasks. The success of this framework lays a solid foundation for the wide application of intelligent robots in the future, and also takes an important step towards the realization of general intelligence.
Paper link:
https://www.nature.com/articles/s42256-025-00983-2