Exploiting Inter-sample and Inter-feature Relations in Dataset Distillation
Dataset distillation has emerged as a promising approach in deep learning, enabling efficient training with small synthetic datasets derived from larger real ones. Particularly, distribution matching-based distillation methods attract attention thanks to its effectiveness and low computational cost. However, these methods face two primary limitations: the dispersed feature distribution within the same class in synthetic datasets, reducing class discrimination, and an exclusive focus on mean feature consistency, lacking precision and comprehensiveness. To address these challenges, we introduce two novel constraints: a class centralization constraint and a covariance matching constraint. The class centralization constraint aims to enhance class discrimination by more closely clustering samples within classes. The covariance matching constraint seeks to achieve more accurate feature distribution matching between real and synthetic datasets through local feature covariance matrices, particularly beneficial when sample sizes are much smaller than the number of features. Experiments demonstrate notable improvements with these constraints, yielding performance boosts of up to 6.6% on CIFAR10, 2.9% on SVHN, 2.5% on CIFAR100, and 2.5% on TinyImageNet, compared to the state-of-the-art relevant methods. In addition, our method maintains robust performance in cross-architecture settings, with a maximum performance drop of 1.7% on four architectures. Code is available at this https URL.

Links:https://arxiv.org/abs/2404.00563
Woven Fabric Capture with a Reflection-Transmission Photo Pair
Digitizing woven fabrics would be valuable for many applications, from digital humans to interior design. Previous work introduces a lightweight woven fabric acquisition approach by capturing a single reflection image and estimating the fabric parameters with a differentiable geometric and shading model. The renderings of the estimated fabric parameters can closely match the photo; however, the captured reflection image is insufficient to fully characterize the fabric sample reflectance. For instance, fabrics with different thicknesses might have similar reflection images but lead to significantly different transmission. We propose to recover the woven fabric parameters from two captured images: reflection and transmission. At the core of our method is a differentiable bidirectional scattering distribution function (BSDF) model, handling reflection and transmission, including single and multiple scattering. We propose a two-layer model, where the single scattering uses an SGGX phase function as in previous work, and multiple scattering uses a new azimuthally-invariant microflake definition, which we term ASGGX. This new fabric BSDF model closely matches real woven fabrics in both reflection and transmission. We use a simple setup for capturing reflection and transmission photos with a cell phone camera and two point lights, and estimate the fabric parameters via a lightweight network, together with a differentiable optimization. We also model the out-of-focus effects explicitly with a simple solution to match the thin-lens camera better. As a result, the renderings of the estimated parameters can agree with the input images on both reflection and transmission for the first time. The code for this paper is at https://github.com/lxtyin/FabricBTDF-Recovery.}

Link::https://wangningbei.github.io/2024/FabricBTDF.html
TensoSDF: Roughness-aware Tensorial Representation for Robust Geometry and Material Reconstruction
Reconstructing objects with realistic mterials from multi-view images is problematic, since it is highly ill-posed. Although the neural reconstruction approaches have exhibited impressive reconstruction ability, they are designed for objects with specific materials (e.g., diffuse or specular materials). To thie end, we propose a novel framework for robust geometry and material reconstruction, where the geometry is expressed with the implicit signed distance field (SDF) encoded by a tensorial representation, namely TensoSDF. At the core of our method is the roughness-aware incorporation of the radiance and reflectance fields, which enables a robust reconstruction of objects with arbitrary refelctive materials. Furthermore, the tensorial representation of objects with arbitrary reflective materials. Furthermore, the tensorial representation enhace geometry details in the reconstructed surface and reduces the training time. Finally, we estimate the materials using an explicit mesh for efficient intersection computation and an implicit SDF for accurate representation. Consequently, our method can achieve more robust geometry reconstruction, outperform the previous works in terms of relighting quality, and reduce 50% training times and 70% inference time. Codes and datasets are available at http://github.com/Riga2/TensoSDF.

Links: https://wangningbei.github.io/2024/TensoSDF.html
Direct2.5: Diverse Text-to-3D Generation via Multi-view 2.5D Diffusion
Recent advances in generative AI have unveiled significant potential for the creation of 3D content. However, current methods either apply a pre-trained 2D diffusion model with the time-consuming score distillation sampling (SDS), or a direct 3D diffusion model trained on limited 3D data losing generation diversity. In this work, we approach the problem by employing a multi-view 2.5D diffusion fine-tuned from a pre-trained 2D diffusion model. The multi-view 2.5D diffusion directly models the structural distribution of 3D data, while still maintaining the strong generalization ability of the original 2D diffusion model, filling the gap between 2D diffusion-based and direct 3D diffusion-based methods for 3D content generation. During inference, multi-view normal maps are generated using the 2.5D diffusion, and a novel differentiable rasterization scheme is introduced to fuse the almost consistent multi-view normal maps into a consistent 3D model. We further design a normal-conditioned multi-view image generation module for fast appearance generation given the 3D geometry. Our method is a one-pass diffusion process and does not require any SDS optimization as post-processing. We demonstrate through extensive experiments that, our direct 2.5D generation with the specially-designed fusion scheme can achieve diverse, mode-seeking-free, and high-fidelity 3D content generation in only 10 seconds. Project page: this https URL.

Links:https://arxiv.org/abs/2311.15980
Gaussian-Flow: 4D Reconstruction with Dynamic 3D Gaussian Particle
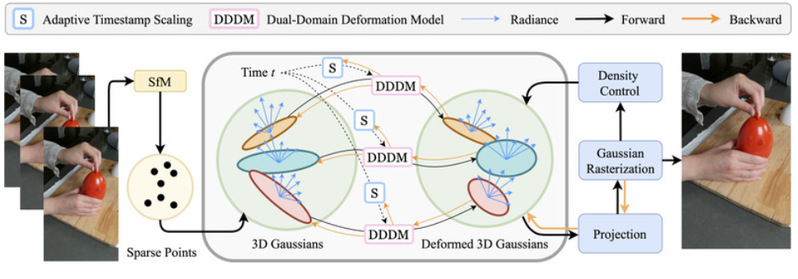
We introduce Gaussian-Flow, a novel point-based approach for fast dynamic scene reconstruction and real-time rendering from both multi-view and monocular videos. In contrast to the prevalent NeRF-based approaches hampered by slow training and rendering speeds, our approach harnesses recent advancements in point-based 3D Gaussian Splatting (3DGS). Specifically, a novel Dual-Domain Deformation Model (DDDM) is proposed to explicitly model attribute deformations of each Gaussian point, where the time-dependent residual of each attribute is captured by a polynomial fitting in the time domain, and a Fourier series fitting in the frequency domain. The proposed DDDM is capable of modeling complex scene deformations across long video footage, eliminating the need for training separate 3DGS for each frame or introducing an additional implicit neural field to model 3D dynamics. Moreover, the explicit deformation modeling for discretized Gaussian points ensures ultra-fast training and rendering of a 4D scene, which is comparable to the original 3DGS designed for static 3D reconstruction. Our proposed approach showcases a substantial efficiency improvement, achieving a [Math Processing Error] faster training speed compared to the per-frame 3DGS modeling. In addition, quantitative results demonstrate that the proposed Gaussian-Flow significantly outperforms previous leading methods in novel view rendering quality. Project page: this https URL
Links:https://arxiv.org/abs/2312.03431