ONNXPruner – A General Model Pruning Adapter Based on ONNX (TPAMI 2025)
Deep and large-scale models, though powerful, often suffer from limited applicability in resource-constrained devices due to their substantial parameter sizes and computational demands. To address this challenge, Prof. Wenbin Li’s team from the School of Intelligence Science and Technology at Nanjing University has proposed ONNXPruner, a general, cross-model and cross-platform model pruning adapter targeting downstream deployment environments.
ONNXPruner establishes a bridge for efficiently applying model pruning techniques on edge and backend devices. It introduces a novel node-affiliation tree structure to automatically adapt to various model architectures and clearly represent node dependencies, thereby guiding the pruning process. Additionally, the adapter incorporates a tree-level evaluation strategy that overcomes the limitations of node-level assessments, improving pruning performance without requiring extra intervention.
Extensive experiments across more than 10 deep and large models on 4 different development platforms demonstrate ONNXPruner’s high adaptability and effectiveness. It significantly shortens the pruning cycle and reduces technical complexity, thereby enhancing the practical usability of model pruning in engineering applications. This work has been accepted by the IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), a top-tier journal in the field of artificial intelligence.
Link:https://ieeexplore.ieee.org/document/10938408
DOI: 10.1109/TPAMI.2025.3554560
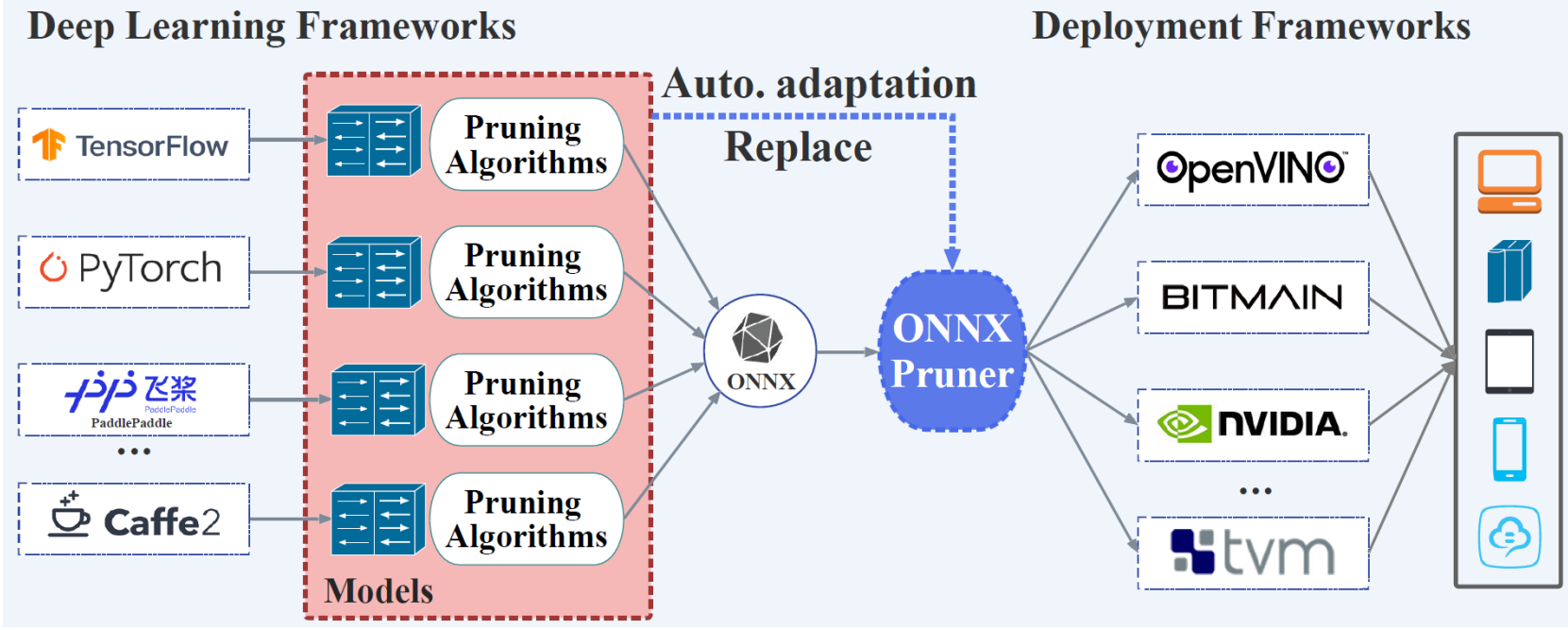
Figure: Schematic Diagram of the ONNXPruner Framework
Frequency-Aware Model Pruning for Image Denoising (TIP 2025)
Model pruning is a commonly used model compression technique aimed at reducing the storage and computational costs of deep neural networks. However, most existing pruning methods are designed for high-level vision tasks, with limited applicability to computationally intensive image denoising networks. To address this gap, Professor Li Wenbin’s team at the School of Intelligence Science and Technology, Nanjing University, proposed a novel filter evaluation method called High-Frequency Component Pruning (HFCP), specifically designed for pruning image denoising networks.
HFCP evaluates the importance of filters based on high-frequency components: the more high-pass a filter is or the more high-frequency energy it generates in feature maps, the more critical it is to the model. This is the first pruning approach tailored to image denoising networks and is effective across various noise types. Moreover, the pruned models using HFCP show an increased proportion of high-frequency information, which helps separate signal from noise.
Experimental results demonstrate that HFCP achieves state-of-the-art performance on four different denoising models, even when pruning 50% of parameters and reducing computational cost by approximately 65%. The related work has been accepted by IEEE Transactions on Image Processing (TIP), 2025.
Link:https://ieeexplore.ieee.org/document/10908464
DOI: 10.1109/TIP.2025.3544108
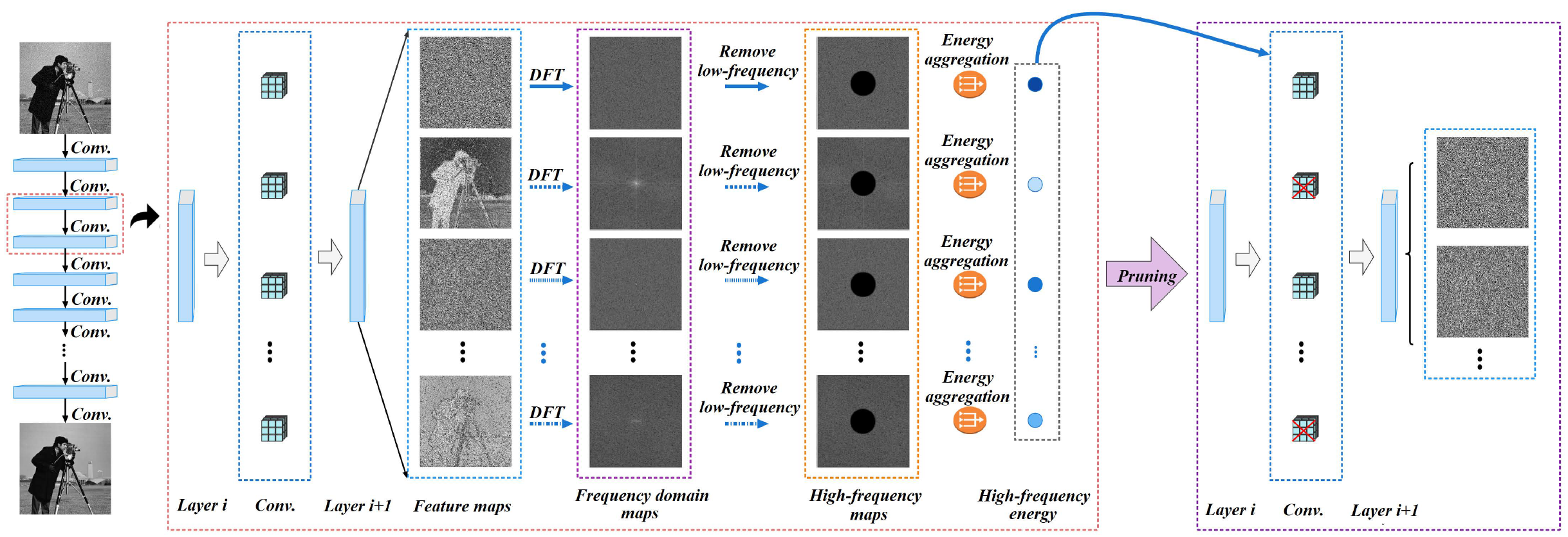
Figure: HFCP framework overview
Class-Incremental Few-Shot Learning via a Training-Free Dual-Level Modality Calibration Strategy (CVPR 2025)
Few-shot class-incremental learning (FSCIL) is a task that enables models to learn new classes with only a limited number of samples. Compared to traditional incremental learning, the scarcity of data in the incremental stage brings additional challenges, such as overfitting. Most existing continual few-shot learning methods rely on vision models and require extra training during the base or incremental stages, leading to higher computational costs and the risk of catastrophic forgetting. To address these issues, Prof. Wenbin Li's team at the School of Intelligence Science and Technology, Nanjing University, has proposed a training-free model adaptation framework based on the CLIP model. This framework incorporates intra-modal and inter-modal calibration strategies. Intra-modal calibration enhances the model's classification ability in both text and vision modalities by utilizing fine-grained class descriptions from large language models alongside visual prototypes from the base task. Inter-modal calibration combines pre-trained language knowledge with task-specific visual priors, reducing modality-specific bias and improving classification accuracy. To further enhance robustness, the framework introduces anisotropic covariance-based distance metrics and cross-modal, class-conditional nearest neighbor measurements, and employs a masked ensemble inference strategy for final classification. This work has been accepted by CVPR 2025, one of the top conferences in the field of computer vision.
Link:https://cvpr.thecvf.com/virtual/2025/poster/33478
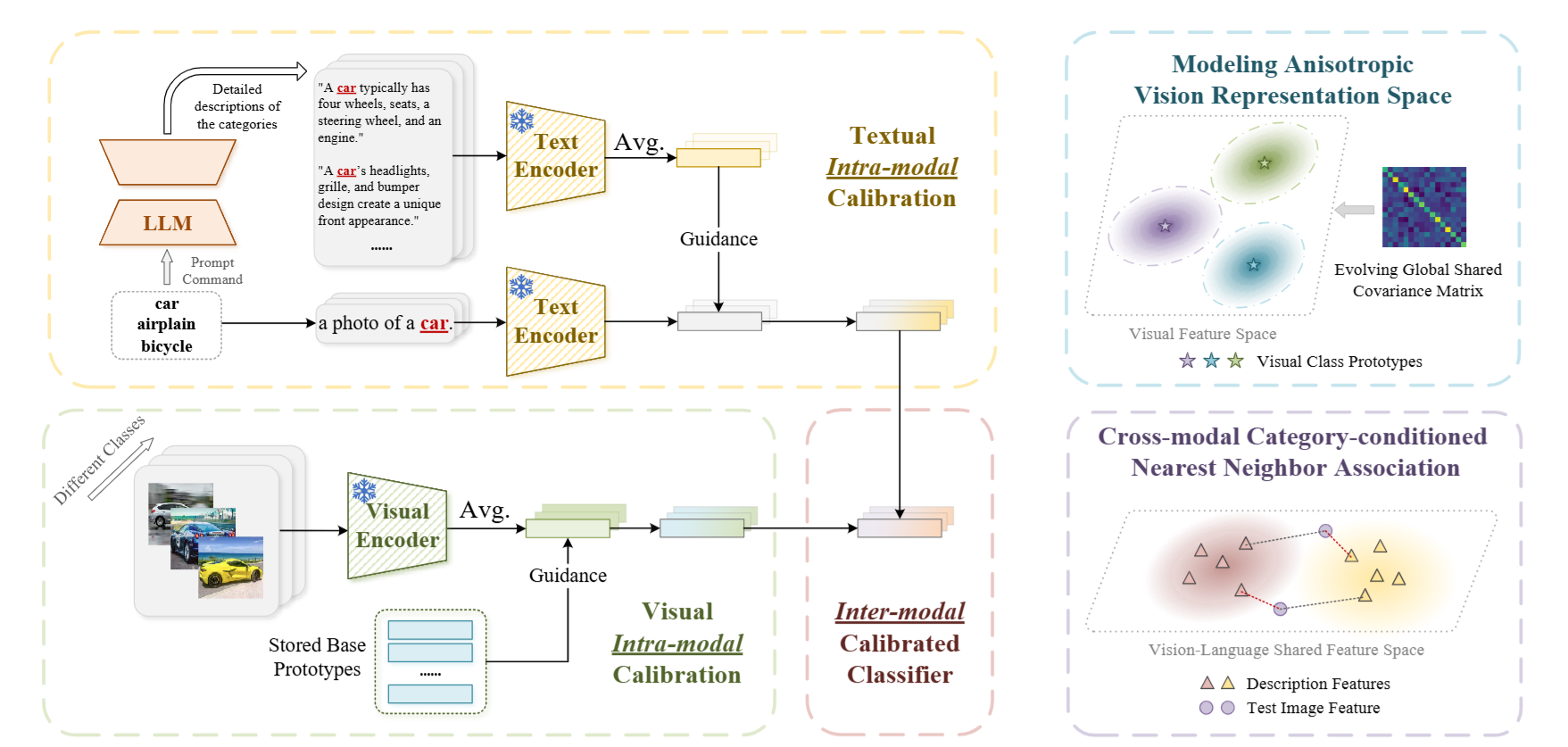
Fig: Framework Diagram of the Proposed Few-shot Class-Incremental Learning Method
Dataset Distillation Method Based on Sample-to-Sample and Feature-to-Feature Relationships (CVPR 2024)
With the development of deep learning, the increasing scale of data has led to significant computational costs in model training. To address this issue, researchers have proposed dataset distillation methods, which extract knowledge from large real-world datasets to smaller synthetic datasets. Dataset distillation has become a key technology for efficient deep learning training and is widely applied in areas such as neural architecture search, continual learning, and privacy protection. The team of Professor Li Wenbin from the School of Intelligence Science and Technology at Nanjing University proposed a dataset distillation method based on sample-to-sample and feature-to-feature relationships. Existing distribution-matching-based dataset distillation methods have two limitations: (1) the feature distributions within the same class in the synthetic dataset are dispersed, lacking class distinguishability; (2) they only focus on average feature consistency, lacking precision and comprehensiveness. To overcome these limitations, two plug-and-play constraints are proposed: (1) a class centering constraint to promote clustering of samples from a specific class, enhancing class distinguishability; (2) a local covariance matrix matching constraint to achieve more accurate feature distribution matching between real and synthetic datasets, even with small sample sizes, through local feature covariance matrices. This work has been accepted at the top computer vision conference CVPR 2024.
Link:
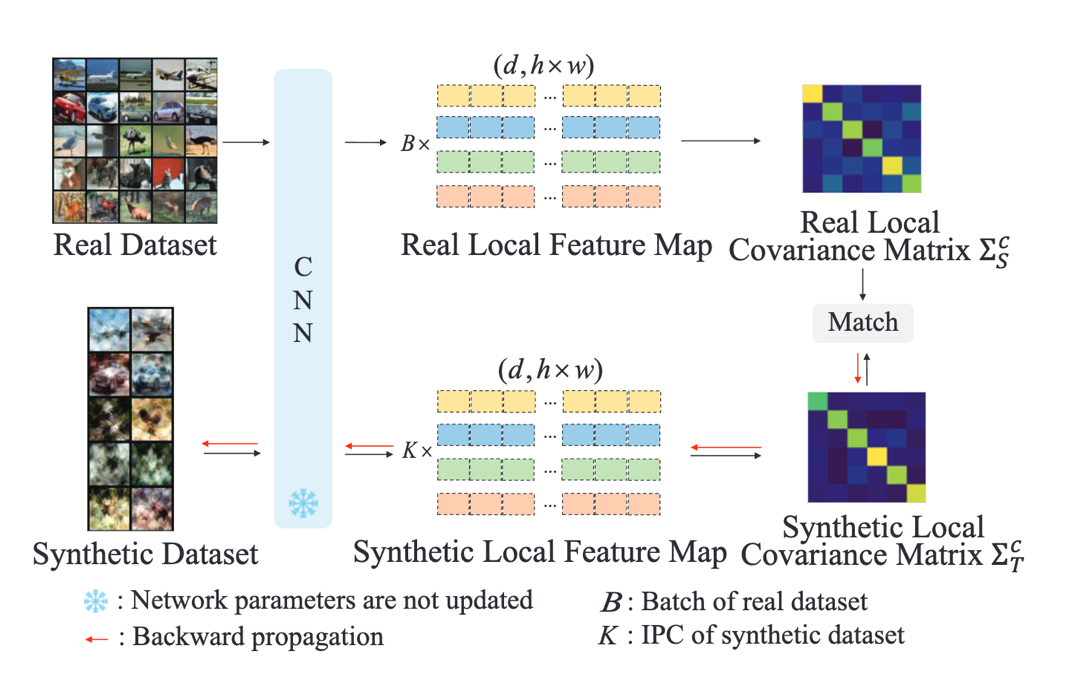
Figure: Framework diagram of the proposed dataset distillation method