Matrix3D: A Foundation Model for Photogrammetry (CVPR 2025 Highlight)
3D content creation is a key technology underpinning a wide range of applications, including mixed reality, digital twins, and film and game production. However, existing approaches often treat generation and reconstruction as two separate tasks: reconstruction relies on dense multi-view inputs, while generation focuses on single or sparse-view settings, making it difficult to model both within a unified framework. At the same time, traditional 3D modeling pipelines—such as Structure-from-Motion (SfM), Multi-View Stereo (MVS), and Novel View Synthesis (NVS)—are fragmented and involve complex, multi-stage processes, posing significant challenges to scalability.
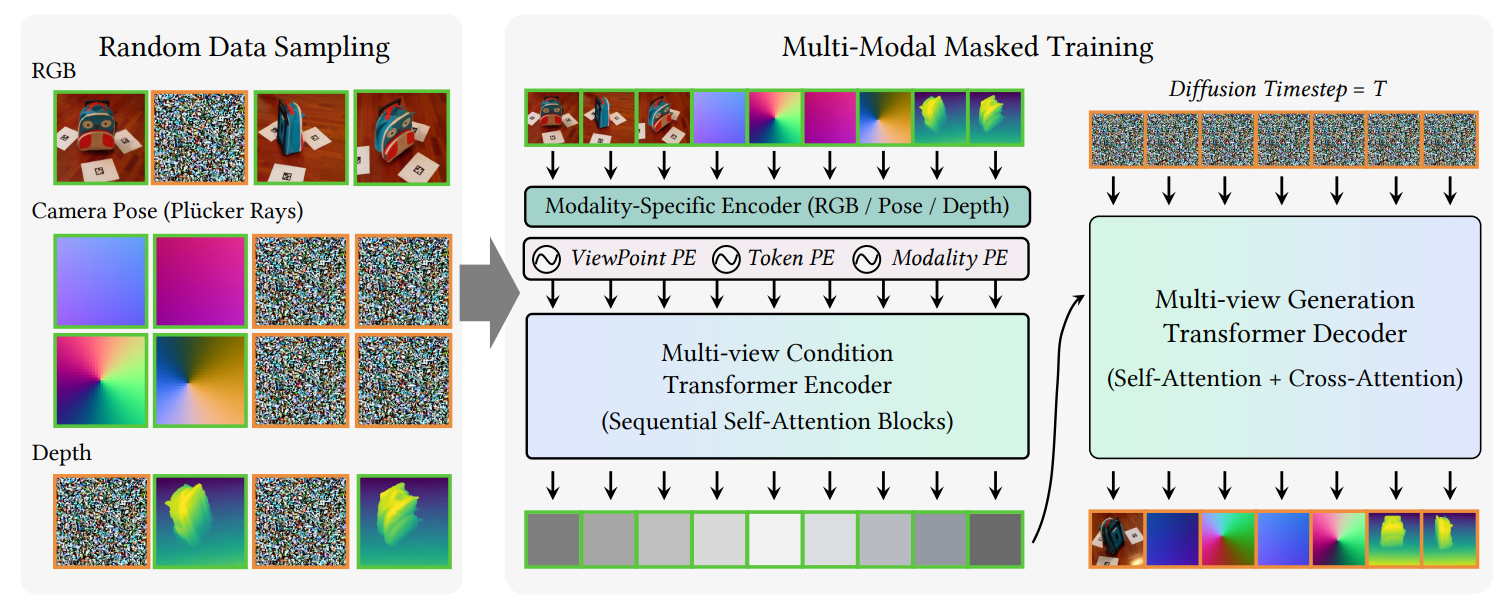
To address the aforementioned challenges, Associate Professor Yao Yao’s team from the School of Intelligence Science and Technology at Nanjing University, in collaboration with Apple and The Hong Kong University of Science and Technology, proposes Matrix3D—the first foundation model for photogrammetry that supports multi-task and multi-modal input-output. Matrix3D leverages masked modeling to jointly learn across multiple modalities, including RGB images, camera poses, and depth maps, unifying the traditionally separate sub-tasks of 3D generation and photogrammetry. This enables cross-modal inference: given any subset of modalities, the model can predict the others. By integrating 3D Gaussian Splatting, Matrix3D is capable of reconstructing high-quality 3D structures from sparse-view inputs with unknown camera poses, significantly streamlining the 3D modeling pipeline. Thanks to its innovative multi-modal diffusion Transformer architecture and cross-modal masked training strategy, Matrix3D can flexibly handle incomplete input modalities and supports arbitrary input-output configurations, achieving state-of-the-art performance across multiple sub-tasks. This work has been accepted by CVPR 2025, one of the top conferences in computer vision, and has been selected as a Highlight Paper.
3D Gaussian Splatting Reconstruction with Pretrained Optical Flow Priors (ICLR 2025)
3D Gaussian Splatting (3DGS) offers impressive rendering quality while enabling fast training and inference. However, its optimization process lacks explicit geometric constraints, making it difficult to reconstruct complete geometry in regions with sparse or missing view observations. To address this limitation, the team led by Associate Professor Yao Yao at the School of Intelligence Science and Technology, Nanjing University, introduces a novel approach that incorporates pretrained matching priors into the 3DGS optimization process. Specifically, they propose Flow Distillation Sampling (FDS), a technique that leverages pretrained geometric knowledge to enhance the accuracy of the Gaussian radiance field. FDS strategically samples unobserved viewpoints adjacent to input views, and computes prior flows between view pairs using a pretrained matching model. These flows are then used to guide the radiance flow derived from the 3DGS geometric structure. Comprehensive experiments on depth rendering, mesh reconstruction, and novel view synthesis demonstrate that FDS significantly outperforms existing state-of-the-art methods. This work has been accepted by ICLR 2025, one of the top conferences in machine learning.
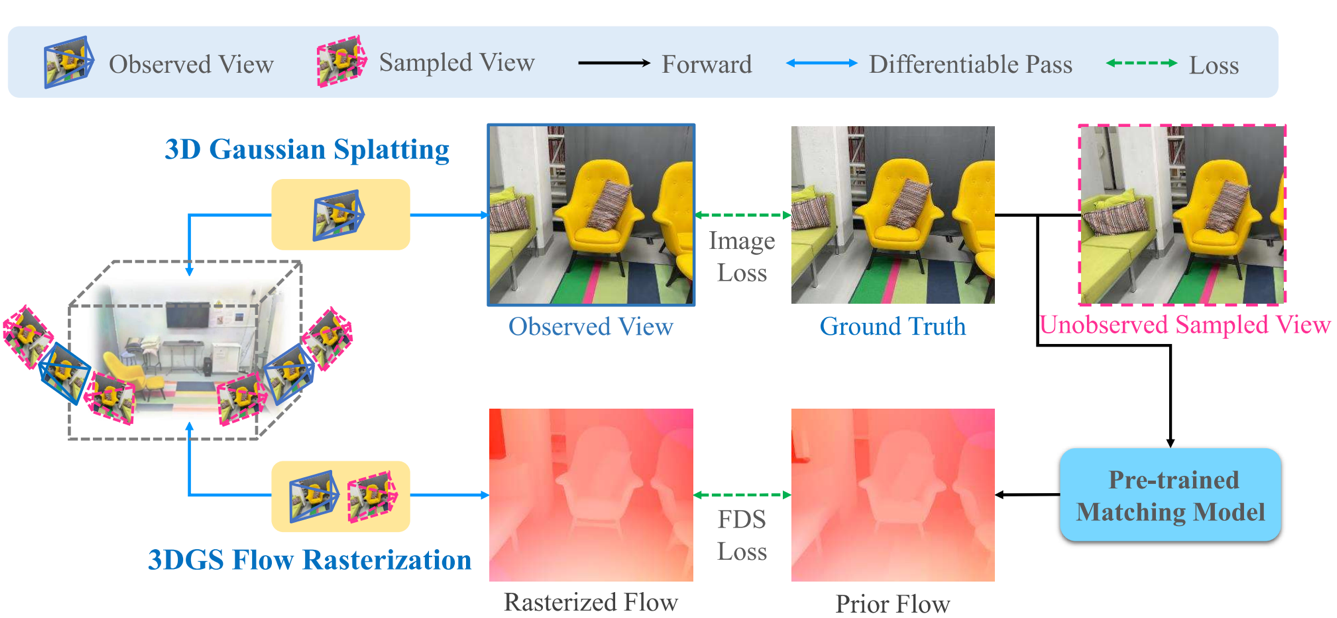
Flow Distillation Sampling - FDS Flowchart
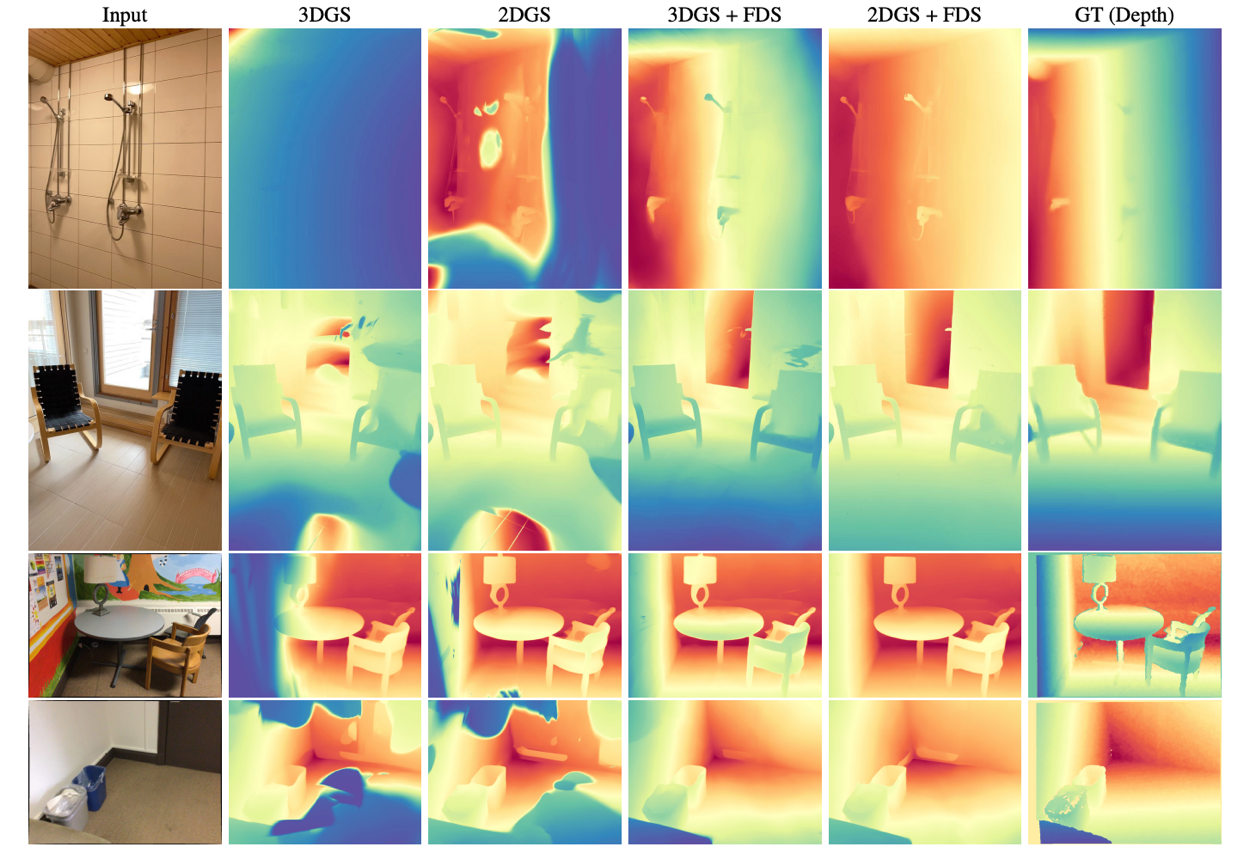
Comparison Results on MushRoom and ScanNet Datasets
EasyHOI: A Novel Large Model-Driven Framework for Hand-Object Interaction Reconstruction (CVPR 2025)
Reconstructing hand-object interactions from a single-view image is a fundamental yet challenging task. Unlike methods based on videos, multi-view images, or predefined 3D templates, single-view reconstruction suffers from inherent ambiguities and occlusions in the image, which significantly hinder reconstruction accuracy. Furthermore, the diversity of hand poses, the variability in object shapes and sizes, and the complexity of interaction patterns add to the difficulty of this task.

To address the above challenges, Associate Professor Xiaoxiao Long from the School of Intelligence Science and Technology, Nanjing University, in collaboration with ShanghaiTech University, The University of Hong Kong, the Max Planck Institute (Germany), and Texas A&M University, proposes EasyHOI—a novel framework for hand-object interaction reconstruction. EasyHOI leverages the strong generalization ability of current foundation models when processing real-world scene images, providing reliable visual and geometric priors for reconstructing hand-object interactions. Building on these priors, EasyHOI introduces an optimization strategy that integrates visual and geometric cues, ensuring that the reconstructed results are not only physically plausible but also consistent with the input 2D images. Thanks to the generative power and generalization ability of large models, EasyHOI outperforms existing baselines across multiple public benchmarks, achieving significant improvements in both accuracy and robustness. It can effectively recover the geometric shapes of objects and fine-grained interaction details from diverse real-world hand-object images. This work presents a new technical paradigm for monocular hand-object interaction reconstruction and shows promising potential for real-world applications. The paper has been accepted by CVPR 2025, one of the top-tier conferences in computer vision.
FATE: High-Fidelity Editable and Animatable 3D Head Reconstruction from Monocular Video (CVPR 2025)
In the task of high-quality 3D head reconstruction, generating editable and animatable full-head avatars from easily accessible monocular video remains a challenging key issue. Despite recent advancements in rendering performance and control capabilities, challenges such as incomplete reconstruction and low expression efficiency still persist. To address this issue, a team led by Assistant Professor Zhu Hao from the School of Intelligence Science and Technology at Nanjing University proposed a novel method, FATE, for reconstructing editable and complete 3D head avatars from monocular video.
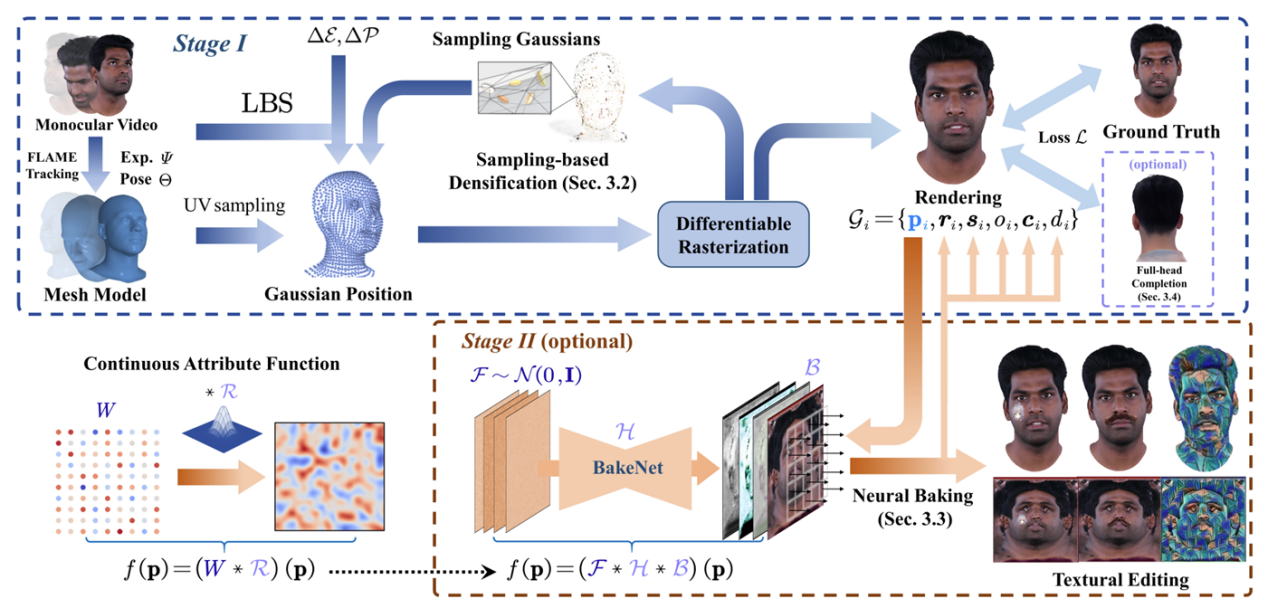
Specifically, the FATE method introduces a sampling-based point density enhancement strategy to optimize the spatial distribution of points, significantly improving rendering efficiency. Additionally, a novel neural baking technique is proposed to convert discrete Gaussian representations into continuous attribute maps, enabling more intuitive appearance editing. Furthermore, FATE designs a general appearance completion framework to restore head appearances in non-frontal regions, enabling full 360-degree renderable 3D avatar reconstruction. Experimental results demonstrate that FATE outperforms existing methods in both qualitative and quantitative evaluations, achieving the current state-of-the-art performance. This work has been accepted for presentation at the top-tier computer vision conference CVPR 2025.
IDOL: An Efficient Solution for Reconstructing Driveable 3D Digital Humans from a Single Image (CVPR 2025)
In fields such as virtual reality, gaming, and 3D content creation, the challenge of how to quickly and accurately reconstruct a driveable full-body 3D human from a single image has been a long-standing problem. Due to the high complexity of human posture and shape, as well as the lack of existing data, traditional methods either rely on multi-view 3D datasets, which struggle to balance generalization and accuracy, or they face challenges in real-time performance, often failing to meet practical application requirements. To address this challenge, Assistant Professor Zhu Hao’s team at the School of Intelligence Science and Technology, Nanjing University, in collaboration with Tencent AI Lab, the Chinese Academy of Sciences, and Tsinghua University, proposed a novel solution, IDOL, which was presented at CVPR 2025 and has attracted significant industry attention (with over 3,500 visits to the project’s homepage).
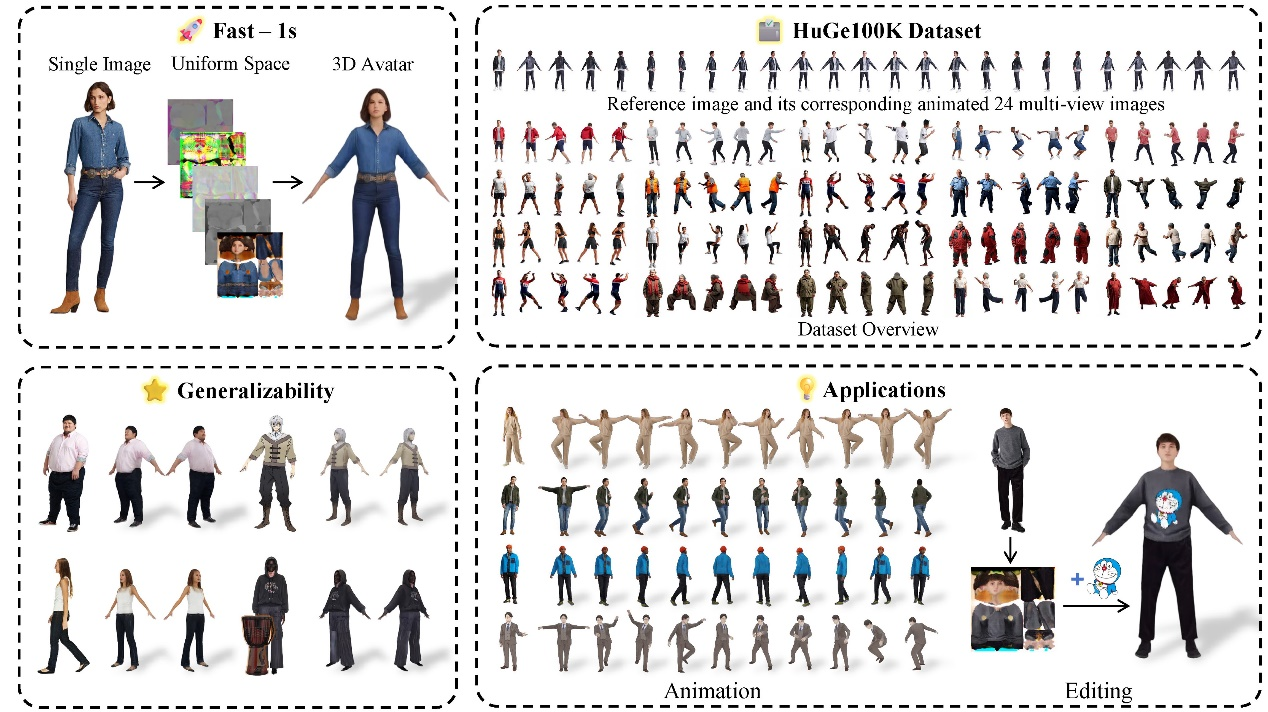
In this method, the researchers first built a large-scale, highly realistic human body dataset, HuGe100K, using their self-developed multi-view generation model. They then trained a feedforward Transformer network, which can generate high-resolution, driveable 3D human models from a single image in just one second. This model has achieved breakthrough results in terms of visual realism, generalization ability, and real-time performance, and it supports a variety of applications, including subsequent rendering, animation, and shape/texture editing. The work has now been open-sourced, and more details can be found at https://yiyuzhuang.github.io/IDOL.