A compressed state representation learning method for multi-agent tasks with rich observations
In some observable multi-agent tasks, the current mainstream multi-agent reinforcement learning algorithms improve the efficiency of agent collaboration policy learning by directly accessing the state during the training phase. However, this condition is often not met in real-life multi-agent tasks. Therefore, it is crucial to achieve state representation learning for partially observable multi-agent tasks. In response to this issue, Professor Gao Yang's team from the School of Intelligent Science and Technology at Nanjing University focuses on multi-agent tasks with rich observation hypotheses. They propose the Task Informed Partially Observable Stochastic Game to formalize the compressed state representation learning problem in such tasks and propose the corresponding solution algorithm STAR.
Specifically, the STAR algorithm divides compressed state representation learning into two sub steps: spatial representation compression and temporal representation compression. Spatial representation compression utilizes information bottleneck theory to learn state representations that approximate the true state of each task for each agent based on joint observation of agents, while temporal representation compression aligns state representations with similar task related features based on bidirectional mutual simulation metrics, achieving efficient learning of compressed state representations. The experimental results show that the STAR algorithm is significantly better than the comparison algorithm on multiple maps in StarCraft, verifying its effectiveness. This job has been accepted by the top conference on artificial intelligence, IJCAI 2024.
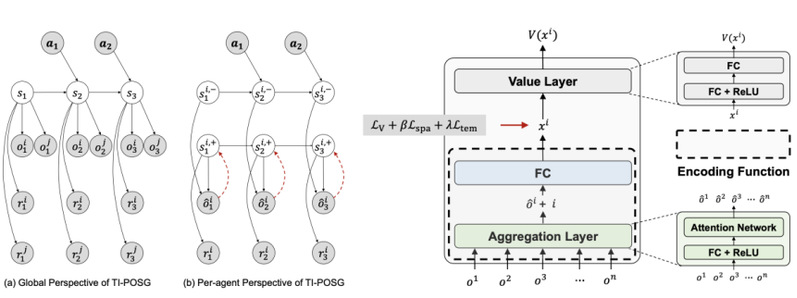
Figure: Schematic diagram of Task Informed Partially Observable Stochastic Game and STAR algorithm structure
Real time rendering of fabric for digital humans
Fabric rendering has been a long-standing research hotspot in the field of graphics, widely used in various fields such as film and television production, game development, and virtual reality. Due to the complex interweaving structure of yarns inside the fabric, low sampling rate rendering leads to rendering noise, while high sampling rate can exponentially increase rendering time, making real-time rendering of multi-scale fabrics a challenge. In response to this issue, Professor Wang Beibei's team from the School of Intelligent Science and Technology at Nanjing University and Professor Wang Lu's team from Shandong University have collaborated to propose a neural representation method suitable for woven fabrics. Based on the regularity and repeatability of woven fabric textures, this method designs an encoder to achieve feature extraction in a lower dimensional feature space. Based on the features extracted from different fabric materials, a unified lightweight decoder is further designed to query and represent the materials. The experimental results show that this method can achieve multi-scale high-quality rendering of woven fabrics at nearly 60 frames per second, while also supporting real-time modification and adjustment of various properties of fabric materials. Compared to previous methods, this method has generalization within the common types of woven fabrics included in the dataset, without the need to train and optimize each material separately. This work has been accepted and published by SIGGRAPH in 2024.
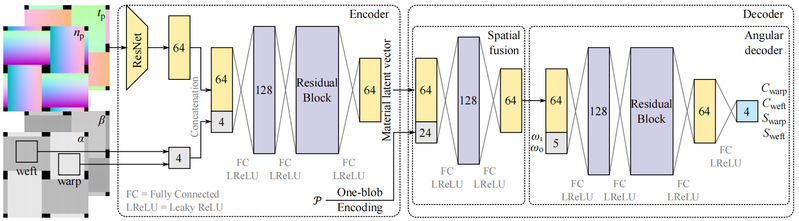
Schematic diagram of fabric neural representation network structure

Display of fabric neural rendering results
Links:https://wangningbei.github.io/2024/NeuralCloth.html
Neural real-time rendering super-resolution based on radiometric brightness demodulation
With the continuous improvement of display device resolution in recent times, the cost of directly rendering high-resolution images in real-time applications such as electronic games remains very high. As a result, super-resolution technology is gradually becoming popular in the field of real-time rendering, such as Nvidia's DLSS and AMD's FSR series. However, preserving high-frequency texture details while maintaining temporal stability and avoiding aliasing issues such as ghosting in real-time rendering of super-resolution remains a challenging task. To address this issue, Professor Wang Beibei from the School of Intelligent Science and Technology at Nanjing University, Professor Wang Lu from Shandong University, and researchers from the Hong Kong Polytechnic University have proposed a neural real-time rendering super-resolution method based on radiometric brightness demodulation. In the article, by introducing the idea of radiometric brightness demodulation, the rendered image is divided into material components and lighting components, and only smoother lighting components are subjected to neural super-resolution, thereby avoiding the loss of texture details. The article also proposes a reliable time-domain reprojection module and a frame recurrent neural super-resolution network, further ensuring time-domain stability and producing high-quality results, making this method superior to existing super-resolution methods in terms of vision and multiple indicators. This work has been accepted and published by CVPR 2024.

Comparison of visual quality with other super-resolution methods
Links: https://arxiv.org/abs/2308.06699
SemanticHuman HD: high-resolution semantic decoupling 3D human body generation
SemanticHuman-HD is a research achievement involving Associate Professor Yi Zili from the School of Intelligent Science and Technology at Nanjing University. It proposes a novel 3D human image synthesis method that can achieve semantic decoupling of human images at high resolution. This technology involves a two-stage training process, first generating images containing human body, depth map, and semantic mask at lower resolutions, and then applying a 3D perceptual super-resolution module in the second stage, significantly improving image quality to a resolution of 1024 x 1024. The uniqueness of SemanticHuman-HD lies in its ability to independently control and generate different semantic parts of the human body, such as the body, top, outerwear, pants, shoes, and accessories.
This method utilizes depth maps and semantic masks as guidance to optimize the number of sampling points in the volume rendering process, effectively reducing computational costs. SemanticHuman-HD not only achieves technological innovation, but also offers a wide range of potential applications, including 3D clothing generation, semantic perception virtual fitting, controllable image synthesis, and cross domain image synthesis. Through ablation research, the paper validated the effectiveness of each component of the proposed method and demonstrated its superior performance compared to existing state-of-the-art methods in both quantitative and qualitative evaluations. The research results of SemanticHuman-HD have opened up new possibilities for human image synthesis technology in the field of artificial intelligence.
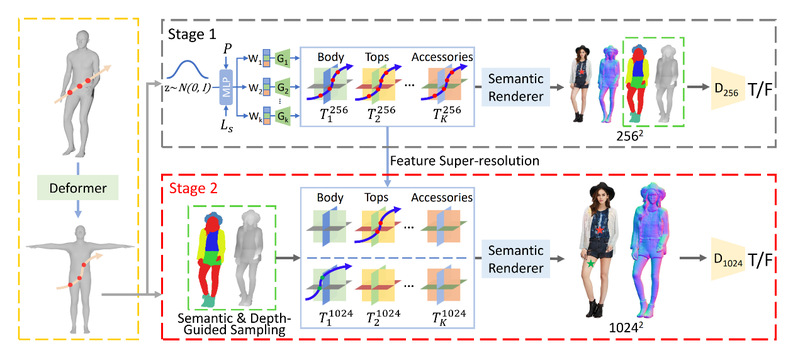
Figure: Schematic diagram of SemanticHuman-HD method
Links: https://arxiv.org/abs/2403.10166
Short term and imminent precipitation prediction method based on learning from long short radar echo sequences
In recent years, data-driven methods equipped with Long Short Term Memory (LSTM) based on radar echo data have become the mainstream for short-term precipitation forecasting tasks. These methods typically take radar echo sequences as inputs and focus on learning the temporal characteristics of precipitation. However, due to the limited modeling ability of these LSTM modules for precipitation characteristics, they are unable to fully capture the spatial distribution and temporal motion characteristics of precipitation. To address this issue, Professor Yuan Xiaotong's team from the School of Intelligent Science and Technology at Nanjing University has proposed a Short Term Precipitation Prediction Method (SLTSL) for learning long short radar echo sequences.
Specifically, SLTSL mainly includes a Short Radar Echo Sequence Learning Module (SSLM) and a Long Radar Echo Sequence Learning Module (LSLM). SSLM uses multiple weighting operations to weight the spatial distribution characteristics of precipitation in short radar echo sequences. Among them, SSLM obtains a short radar echo sequence by concatenating the feature maps of four adjacent moments using a matrix. LSLM fuses all echo images at all time points into a long radar echo sequence through matrix fusion, and then captures the temporal motion characteristics of precipitation at each time point from the long radar echo sequence through multi-state transformation and aggregation. To verify the performance of this method, we conducted experiments on three publicly available datasets: RadarCIKM, TAASRAD19, and RadarKNMI. The experimental results indicate that the forecasting method proposed in this study is superior to other advanced methods. This work has been accepted by the top issue of remote sensing, TGRS.
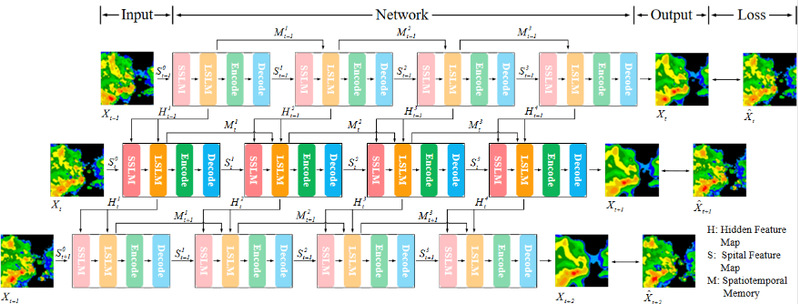
Figure 1: Schematic diagram of the short impending precipitation prediction method (SLTSL) for learning long short radar echo sequences
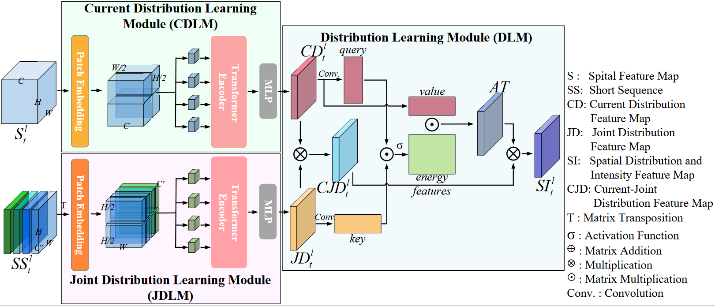
Figure 2: Schematic diagram of the structure of the Short Radar Echo Sequence Learning Module (SSLM)
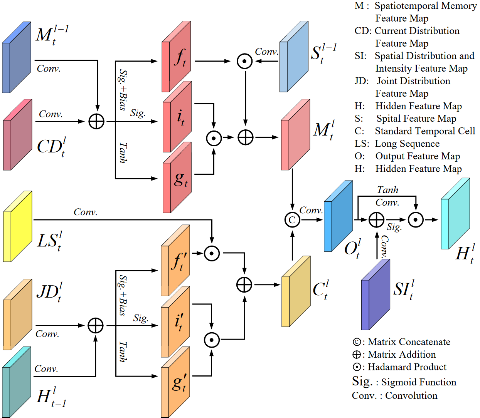
Figure 3: Schematic diagram of the structure of the Long Radar Echo Sequence Learning Module (LSLM)